引言
得益于数据获取成本大幅降低和算力的提升,原本在学术界相对“沉寂”的多层感知机、卷积神经网络、长短期记忆网络等经典模型,在过去十余年间被重新挖掘并得到了广泛应用,尤其是在图像识别、自然语言处理等领域,这些模型取得了突破性的进展。与此同时,强化学习也因其在游戏、机器人控制等领域的出色表现而备受关注,成为了深度学习研究的热点之一。
深度学习领域的快速发展离不开高效的工具支持。早期的深度学习框架,如Theano、Caffe和Torch,为研究者提供了基础的工具,推动了该领域的开创性研究,这其中的许多经典论文的设想验证都是基于这些框架实现的。
随着深度学习的普及,对框架性能和易用性的需求也越来越高。TensorFlow和Caffe2等框架应运而生,它们提供了更完善的功能和更强大的性能,逐渐成为了主流选择。其中,TensorFlow的高级API Keras更是大大降低了深度学习的门槛。
为了进一步提升开发效率和灵活性,Chainer率先引入了命令式编程的理念,将深度学习模型的定义与Python的数值计算库NumPy紧密结合。这种方式使得模型的构建更加直观和灵活。随后,PyTorch、MXNet的Gluon API以及Jax等框架纷纷采用了类似的设计,使得深度学习的开发体验更接近传统的Python编程。本系列文章将使用PyTorch作为主要学习框架。
图0-1来自Paper with code网站,颜色面积代表使用该框架的论文公开代码库的数量,截至2025年2月,基于PyTorch的代码实现(红色部分)真可谓是一骑绝尘。
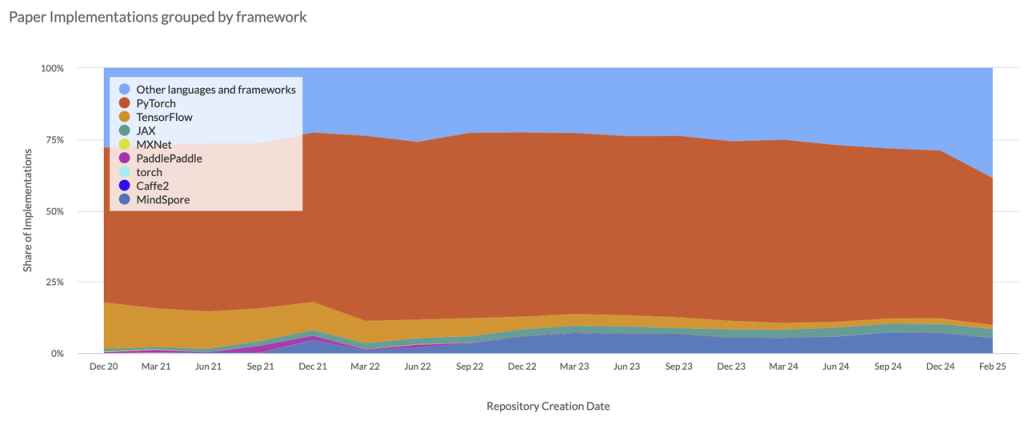
图 0-1
“All in PyTorch”,准备好了吗?
PyTorch 是一个广泛使用的开源机器学习框架,由 Facebook 的人工智能研究实验室 (FAIR) 开发和维护。它主要用于深度学习应用,包括计算机视觉、自然语言处理等领域。PyTorch 提供了灵活的 API 和动态计算图,能够快速构建和训练复杂的神经网络模型。
以下是 PyTorch 的关键特点:
- 动态计算图:
- PyTorch 使用动态计算图,这意味着开发者可以在运行时构建和修改网络结构。这与静态图框架(如 TensorFlow 早期版本)不同,在静态图框架中,需要先定义整个计算流程再执行。
- GPU 加速:
- PyTorch 支持使用 GPU 进行高效的数值计算,可以通过简单的 API 调用来实现数据和模型在 GPU 上的运行。
- 支持多 GPU 训练和分布式训练,适用于大规模数据集。
- 自动微分:
- PyTorch 提供了自动求导功能,通过
torch.autograd模块实现。这意味着可以很容易地对神经网络的参数进行求导,以计算梯度。
- PyTorch 提供了自动求导功能,通过
在 PyTorch2.0中(截止到2025年2月,最新版是2.6),引入了更多新特性,总结来说包括:
- torch.compile: 这是 PyTorch 2.0 的核心特性。它是一个编译器,可以将 PyTorch 模型编译成高效的机器码,从而大幅提升模型的执行速度。通过一行代码,就可以将训练速度提升数十倍。值得一提的是,torch.compile增加了对python3.13的支持。
- 加速 Transformer: PyTorch 2.0 引入了 Accelerated Transformers,这是一种高度优化的 Transformer 实现,可以显著加速自然语言处理任务。
- MPS 后端(Metal Performance Shaders ): PyTorch 2.0 支持 MPS 后端,可以在 Mac 平台上利用 GPU 进行加速。
- 动态形状支持: PyTorch 2.0 增强了对动态形状的支持,使得模型可以处理不同形状的输入数据,提高了模型的灵活性。
- 分布式训练优化: PyTorch 2.0 对分布式训练进行了优化,使得模型可以在多台机器上并行训练,加快训练速度。
- 与 Python 的更紧密集成: PyTorch 2.0 与 Python 的集成更加紧密,使得代码编写更加简洁、高效。
总之,对于PyTorch,记住三个核心概念即可。
- PyTorch 是一个张量库,它扩展了数组编程库 NumPy 的概念,并增加了在 GPU 上加速计算的功能,从而实现了 CPU 和 GPU 之间的无缝切换。
- 其次,PyTorch 是一个自动求导引擎,也被称为 autograd,它可以自动计算张量操作的梯度,简化了反向传播和模型优化的过程。
- 最后,PyTorch 是一个深度学习库,这意味着它提供了模块化、灵活且高效的构建模块(包括预训练模型、损失函数和优化器),可用于设计和训练各种深度学习模型。
- 本章余下内容,介绍PyTorch的基本用法和常用的高级用法,在后续的章节章回反复用到这些内容。
基础概念和操作
标量(scalar)
一个标量就是一个单独的数。
向量(vector)
一个向量是一列数。这些数是有序排列的。通过次序中的索引,我们可以确定每个单独的数。
矩阵(matrix)
矩阵是一个二维数组,其中的每一个元素由两个索引(而非一个)所确定。
张量 (tensor)
张量表示一个由数值组成的数组,这个数组可能有多个维度。特别的,向量(vector)是具有一个轴的张量; 矩阵(matrix)是具有两个轴的张量 。张量中的每个值都称为张量的元素(element) 。
import torch
>>> tensor0d = torch.tensor(1)
>>> tensor1d = torch.tensor([1, 2, 3])
>>> tensor2d = torch.tensor([[1, 2], [3, 4]])
>>> tensor3d = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])使用过Python中NumPy计算包的读者会对本部分很熟悉,无论使用哪个深度学习框架,它的张量类(在MXNet中为ndarray,在PyTorch和TensorFlow中为Tensor)都与Numpy的ndarray类似。但深度学习框架又比Numpy的ndarray多一些重要功能:
- GPU很好地支持加速计算,而NumPy仅支持CPU计算;
- 张量类支持自动微分。这些功能使得张量类更适合深度学习;
创建张量 (tensor)
常见的构造Tensor的方法:
| 函数 | 功能 |
| tensor(sizes) | 基础构造函数 |
| tensor(data) | 类似于np.array |
| ones(sizes) | 全1 |
| zeros(sizes) | 全0 |
| eye(sizes) | 对角为1,其余为0 |
| arange(s,e,step) | 从s到e,步长为step |
| linspace(s,e,steps) | 从s到e,均匀分成step份 |
| rand/randn(sizes) | rand是[0,1)均匀分布;randn是服从N(0,1)的正态分布 |
| normal(mean,std) | 正态分布(均值为mean,标准差是std) |
| randperm(m) | 随机排列 |
#使用 arange 创建一个行向量 x
>>> import torch
>>> torch.arange(12)
>>> tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
#通过张量的shape属性来访问张量(沿每个轴的长度)的形状
>>> x.shape
>>> torch.Size([12])
>>> x.size() #同x.shape
>>> x.dtype #获取张量的数据类型
>>> x.device #获取张量所在的设备(CPU 或 GPU)
#通过numel() 函数获取张量元素的总数
>>> x.numel()
>>> 12
#通过reshape函数调整张量的形状
#这里获得了一个3行4列的矩阵。
>>> x.reshape(3,4)
>>> tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
#当然,还可以通过-1来调用此自动计算出维度的功能。
#用x.reshape(-1,4)或x.reshape(3,-1)来取代x.reshape(3,4)
#有时希望使用全0、全1、其他常量,或者从特定分布中随机采样的数字来初始化矩阵
#创建 一个形状为(2,3,4)的张量,其中所有元素都设置为0
>>> torch.zeros((2, 3, 4))
>>> tensor([[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]])
#同样,创建一个形状为(2,3,4)的张量,其中所有元素都设置为1
>>> torch.ones((2, 3, 4))
>>> tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
#从高斯分布中随机采样
>>> torch.randn(3, 4)
>>> tensor([[0.8071, 0.7062, 0.8271, 0.2214],
[0.8966, 0.5199, 0.0523, 0.9337],
[0.6717, 0.6878, 0.5099, 0.0991]])
#通过列表赋值
>>> torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
>>> tensor([[2, 1, 4, 3],
[1, 2, 3, 4],
[4, 3, 2, 1]])
#保存张量到文件
>>> torch.save(tensor, './tensor.pt')
#从文件加载张量
>>> torch.load("./tensor.pt")基本运算
对于任意具有相同形状的张量,常见的标准算术运算符(+、-、*、/和**)都可以被升级为按元素运算。
# 按元素计算
>>> x = torch.tensor([1.0, 2, 4, 8])
>>> y = torch.tensor([2, 2, 2, 2])
>>> x + y, x - y, x * y, x / y, x ** y
>>> (tensor([ 3., 4., 6., 10.]),
tensor([-1., 0., 2., 6.]),
tensor([ 2., 4., 8., 16.]),
tensor([0.5000, 1.0000, 2.0000, 4.0000]),
tensor([ 1., 4., 16., 64.]))
#求幂
>>> torch.exp(x)
>>> tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])
#点积
>>> x = torch.tensor([1, 2, 4, 8])
>>> y = torch.tensor([2, 2, 2, 2])
>>> torch.dot(x, y)
>>> tensor(30)
#矩阵乘法
>>> x = torch.tensor([[1, 2], [4, 8]])
>>> y = torch.tensor([[2, 2], [2, 2]])
>>> torch.matmul(x,y)
>>> tensor([[ 6, 6],
[24, 24]])
#元素拼接
>>> X = torch.arange(12, dtype=torch.float32).reshape((3,4))
>>> Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
>>> torch.cat((X, Y), dim=0),torch.cat((X, Y), dim=1)
>>> (tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[ 2., 1., 4., 3.],
[ 1., 2., 3., 4.],
[ 4., 3., 2., 1.]]),
tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],
[ 4., 5., 6., 7., 1., 2., 3., 4.],
[ 8., 9., 10., 11., 4., 3., 2., 1.]]))
#求和
>>> X.sum()
>>> tensor(66.)
#比较
>>> X==Y
>>> tensor([[False, True, False, True],
[False, False, False, False],
[False, False, False, False]])
#广播
#不同形状的张量相加
1. 通过适当复制元素来扩展一个或两个数组,以便在转换之后,两个张量具有相同的形状
2. 对生成的数组执行按元素操作
3. 在大多数情况下,我们将沿着数组中长度为1的轴进行广播
>>> a = torch.arange(3).reshape((3, 1))
>>> b = torch.arange(2).reshape((1, 2))
>>> a+b
>>> tensor([[0, 1],
[1, 2],
[2, 3]])
#其他操作
>>> torch.cross(X, Y) # 向量积(叉积)
>>> X.mean(dim=None) # 沿着给定维度求均值
>>> X.max(dim=None) # 沿着给定维度求最大值
>>> X.min(dim=None) # 沿着给定维度求最小值
>>> X.transpose(dim0, dim1) # 交换两个维度
>>> X.permute(*dims) # 重新排列维度
>>> X.view(new_shape) # 改变张量的形状
>>> X.reshape(new_shape) # 同 tensor.view(new_shape)
>>> X.unsqueeze(dim) # 在给定维度增加一个新轴
>>> X.squeeze(dim=None) # 删除单维度条目(大小为1的维度)注意 torch.view() 返回的新tensor与源tensor共享内存(其实是同一个tensor),更改其中的一个,另外一个也会跟着改变。推荐的方法是我们先用 clone() 创造一个张量副本然后再使用 torch.view()进行函数维度变换 。
索引和切片
和Python数组中一样,张量中的元素可以通过索引和切片访问。需要注意的是:pytorch索引出来的结果与原数据共享内存,修改一个,另一个会跟着修改。如果不想修改,可以考虑使用copy()等方法。
>>> X = torch.arange(12, dtype=torch.float32).reshape((3,4))
>>> X[:-1]
>>> tensor([[0., 1., 2., 3.],
[4., 5., 6., 7.]])
>>> X[2:3]
>>> tensor([[ 8., 9., 10., 11.]])
>>> X[0:2,:]
>>> tensor([[0., 1., 2., 3.],
[4., 5., 6., 7.]])自动微分
自动微分(Automatic Differentiation, AD)是一种数值方法,用于高效计算函数的导数。在深度学习中,我们通常需要计算损失函数相对于模型参数的梯度,以便通过梯度下降算法更新模型参数。PyTorch 的自动微分功能通过 torch.autograd 模块实现。
- 记录梯度:
tensor.requires_grad_(True): 设置张量是否需要梯度计算。tensor.grad: 获取张量的梯度。
- 计算梯度:
loss.backward(): 计算损失函数相对于张量的梯度。
- 清零梯度:
optimizer.zero_grad(): 清除优化器中的梯度。
- 分离张量
detach()会创建一个新的张量,该张量与原来的张量共享相同的底层数据,但不再保留历史记录(即不再跟踪梯度)。这意味着对新张量的任何操作都不会被记录到计算图中,从而不会影响梯度的计算。- 为了防止跟踪历史记录(和使用内存),可以将代码块包装在
with torch.no_grad():中
# 创建一个叶子张量
x = torch.tensor([3.0], requires_grad=True)
# 创建一个非叶子张量
y = x ** 2
# 显式地要求保留非叶子张量的梯度
y.retain_grad()
# 计算另一个张量
z = y * 2
# 反向传播
z.backward()
# 查看梯度
print("Gradient of x:", x.grad)
print("Gradient of y:", y.grad)神经网络模块
神经网络模块是 PyTorch 中用于构建和训练神经网络的基础。在 PyTorch 中,神经网络是由一系列层组成的,这些层可以是全连接层、卷积层、池化层等。PyTorch 的 torch.nn 模块提供了这些层以及其他实用工具,如激活函数、损失函数等。
- 定义模型:
class MyModel(nn.Module):: 定义一个自定义模型。model = MyModel(): 创建模型实例。
- 添加层:
- 全连接层 (
nn.Linear):nn.Linear(in_features, out_features, bias=True): 创建一个全连接层。
- 卷积层 (
nn.Conv2d):nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True): 创建一个二维卷积层。
- 池化层 (
nn.MaxPool2d,nn.AvgPool2d):nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False): 创建一个最大池化层。nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None): 创建一个平均池化层。
- 归一化层 (
nn.BatchNorm2d,nn.LayerNorm):nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True): 创建一个批量归一化层。nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True): 创建一个层归一化层。
- 激活函数 (
nn.ReLU,nn.Sigmoid,nn.Tanh):nn.ReLU(inplace=False): ReLU 激活函数。nn.Sigmoid(): Sigmoid 激活函数。nn.Tanh(): Tanh 激活函数。
- 全连接层 (
- 前向传播:
def forward(self, x):: 定义模型的前向传播方法。output = model(input): 使用模型进行前向传播。
- 损失函数:
PyTorch 提供了多种损失函数来衡量模型的输出与真实标签之间的差距。
torch.nn.CrossEntropyLoss(): 交叉熵损失。torch.nn.MSELoss(): 均方误差损失。
初始化器
在深度学习模型的训练中,权重的初始值极为重要,为了利于训练和减少收敛时间,需要对模型进行合理的初始化。PyTorch在torch.nn.init提供了常用的初始化方法。
- torch.nn.init.uniform_(tensor, a=0.0, b=1.0)
填充来自均匀分布 [a, b) 的随机值。
- torch.nn.init.normal_(tensor, mean=0.0, std=1.0)
填充来自正态分布 N(mean, std^2) 的随机值。
- torch.nn.init.constant_(tensor, val)
用常数值 val 填充张量的所有元素。
- torch.nn.init.ones_(tensor)
用 1 填充张量的所有元素。
- torch.nn.init.zeros_(tensor)
用 0 填充张量的所有元素。
- torch.nn.init.eye_(tensor)
将张量填充为单位矩阵(仅适用于方阵)。
- torch.nn.init.dirac_(tensor, groups=1)
将张量填充为 Dirac delta 函数,这是为卷积核设计的一种初始化方法,通常用于深层网络中的特定层。
- torch.nn.init.xavier_uniform_(tensor, gain=1.0)
使用 Xavier 初始化法中的均匀分布来填充张量。Xavier 初始化法旨在保持每一层的激活函数的方差相同,避免梯度消失或爆炸。
- torch.nn.init.xavier_normal_(tensor, gain=1.0)
使用 Xavier 初始化法中的正态分布来填充张量。与均匀分布版本类似,但使用不同的分布方式。
- torch.nn.init.kaiming_uniform_(tensor, a=0, mode=’fan_in’, nonlinearity=’leaky_relu’)
使用 Kaiming 初始化法中的均匀分布来填充张量。Kaiming 初始化法是针对使用 ReLU 或其变体作为激活函数的网络设计的。
- torch.nn.init.kaiming_normal_(tensor, a=0, mode=’fan_in’, nonlinearity=’leaky_relu’)
使用 Kaiming 初始化法中的正态分布来填充张量。与均匀分布版本类似,但使用正态分布。
- torch.nn.init.orthogonal_(tensor, gain=1)
使用正交矩阵来初始化张量。这种方法特别适合于 RNNs 或其他需要长期依赖关系的任务。
- torch.nn.init.sparse_(tensor, sparsity, std=0.01)
将张量初始化为稀疏矩阵。每个列有 sparsity * out_features 的非零项,非零项从正态分布中采样。
import torch
import torch.nn as nn
import torch.nn.init as init
# 创建一个简单的线性层
linear_layer = nn.Linear(10, 10)
# 初始化权重和偏置
init.uniform_(linear_layer.weight, -0.01, 0.01)
init.constant_(linear_layer.bias, 0.01)
# 其他初始化方法
init.normal_(linear_layer.weight, mean=0, std=0.01)
init.ones_(linear_layer.bias)
init.zeros_(linear_layer.weight)
init.zeros_(linear_layer.bias)
init.eye_(linear_layer.weight)
#init.dirac_(linear_layer.weight)
init.xavier_uniform_(linear_layer.weight)
init.xavier_normal_(linear_layer.weight)
init.kaiming_uniform_(linear_layer.weight, mode='fan_in', nonlinearity='relu')
init.kaiming_normal_(linear_layer.weight, mode='fan_in', nonlinearity='relu')
init.orthogonal_(linear_layer.weight)
init.sparse_(linear_layer.weight, sparsity=0.1)
print(linear_layer.weight)
print(linear_layer.bias)优化器
优化器负责根据损失函数计算的梯度来调整模型的权重和其他可学习参数,从而最小化损失函数。常用的优化器包括:
torch.optim.SGD(params, lr): 随机梯度下降优化器,它按照固定的学习率更新参数。torch.optim.Adam(params, lr): Adam 优化器是一种自适应学习率的方法,结合了动量(Momentum)和 RMSprop 的优点,能够自动调整每个参数的学习率。torch.optim.AdamW(params, lr): AdamW 优化器,是 Adam 的改进版,它将权重衰减(weight decay)应用于参数,而不是作为 L2 正则化的一部分。- torch.optim.Adagrad(
params, lr):Adagrad 是一种自适应学习率方法,它为每个参数维护一个累积梯度历史。Adagrad 的学习率会随着训练的进行逐渐减小。 - torch.optim.RMSprop(
params, lr):是一种自适应学习率方法,它通过滑动平均的方式更新每个参数的学习率。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的模型
model = nn.Linear(10, 1)
# 创建一个优化器实例
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 定义损失函数
criterion = nn.MSELoss()
# 假设有一些输入数据和目标数据
inputs = torch.randn(100, 10)
targets = torch.randn(100, 1)
# 训练循环
for epoch in range(10): # 迭代 10 次
optimizer.zero_grad() # 清空梯度
outputs = model(inputs) # 前向传播
loss = criterion(outputs, targets) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
print("Training complete.")模型训练和评估
- 训练循环:
for epoch in range(num_epochs):: 循环遍历每个训练周期。for inputs, labels in dataloader:: 循环遍历数据加载器中的批次。optimizer.step(): 更新模型参数。
- 评估模型:
model.eval(): 设置模型为评估模式。with torch.no_grad():: 禁用梯度计算。
数据加载
PyTorch数据读入是通过Dataset+DataLoader的方式完成的,Dataset定义数据格式和变换形式,DataLoader通过小批量的形式加载数据,支持数据批处理、随机打乱数据、多线程读取等特性。
import torch
from torch.utils.data import DataLoader
#Dataset 的具体实现之一,适用于将几个 Tensor 组合成一个样本。
#通常用于将特征 Tensor 和目标 Tensor 结合在一起
from torch.utils.data import TensorDataset
# 创建一些示例数据
features = torch.randn(100, 10) # 100个样本,每个样本有10个特征
labels = torch.randint(0, 2, (100,)) # 100个标签,假设是二分类问题
# 将特征和标签组合成一个数据集
dataset = TensorDataset(features, labels)
# 使用 DataLoader 来创建一个可迭代的对象
#shuffle:是否将读入的数据打乱,一般在训练集中设置为True,验证集中设置为False
data_loader = DataLoader(dataset, batch_size=20, shuffle=True, num_workers=2)
# 迭代数据
for batch_features, batch_labels in data_loader:
print("Batch Features:", batch_features.size(), "Batch Labels:", batch_labels.size())
break我们会在后续的章节中,补充和扩展Pytorch的用法和技巧。
扩展组件
PyTorch 生态系统非常丰富,以下是一些主要的组件和库,它们扩展了 PyTorch 的功能,使其适用于各种应用场景:
1. TorchVision
- 描述:TorchVision 是 PyTorch 的计算机视觉库,提供了许多常用的图像处理工具和预训练模型。
- 主要模块:
- datasets:常用的数据集(如 CIFAR-10、ImageNet 等)。
- models:预训练模型(如 ResNet、VGG、Inception 等)。
- transforms:图像变换和增强功能。
- utils:辅助工具,如数据可视化。
2. TorchText
- 描述:TorchText 是 PyTorch 的自然语言处理库,提供了文本数据的加载、预处理和特征提取功能。
- 主要模块:
- datasets:常用的数据集(如 IMDB、SNLI 等)。
- data:数据处理工具,如 Field、TabularDataset。
- vocabs:词汇表管理。
- functional:文本处理函数。
3. TorchVideo
- 描述:TorchVideo 是 PyTorch 的视频处理库,提供了视频数据的加载和预处理功能。
- 主要模块:
- datasets:常用的数据集(如 Kinetics、UCF101 等)。
- transforms:视频变换和增强功能。
- io:视频读写工具。
4. TorchElastic
- 描述:TorchElastic 是 PyTorch 的弹性训练库,提供了分布式训练的弹性调度和容错功能。
- 主要功能:
- 弹性调度:动态调整训练任务的资源分配。
- 容错:处理节点故障和恢复训练。
5. TorchServe
- 描述:TorchServe 是 PyTorch 的模型服务库,提供了模型的部署和推理功能。
- 主要功能:
- 模型部署:将训练好的模型部署到生产环境中。
- API 接口:提供 RESTful API 接口进行模型推理。
- 模型管理:管理多个模型版本和配置。
6. TorchRec
- 描述:TorchRec 是 PyTorch 的推荐系统库,提供了推荐系统的构建和优化功能。
- 主要模块:
- models:常见的推荐模型(如 DNN、Wide & Deep、DeepFM 等)。
- datasets:常用的数据集(如 MovieLens、Amazon Reviews 等)。
- optimizers:优化算法,针对推荐系统的特殊需求。
后续的章节中,我们会对涉及的组件进行详细的介绍。