OpenAI在2019年发布了题为《Language Models are Unsupervised Multitask Learners》的论文,论文详细介绍了GPT-2的设计理念、训练方法及其性能表现。以下是论文的一些关键要点:
- 无监督学习:GPT-2展示了如何通过无监督学习来训练一个强大的语言模型。它利用了大量的互联网文本进行预训练,从而学会了处理各种各样的语言任务。
- 变换器架构:GPT-2基于变换器架构,这是一种专门设计用于处理序列数据的深度学习模型。变换器模型的一个关键特点是自注意力机制(self-attention mechanism),它允许模型关注输入序列中的不同部分以构建输出。具体参见论文《 Attention Is All You Need 》
- 大规模训练数据:GPT-2使用的训练数据集非常庞大,包含从Reddit上抓取的8百万个网页,这些网页具有较高的质量(比如至少有3个赞)。
- 多任务适应性:论文强调了GPT-2在多种语言理解任务上的表现,如阅读理解、机器翻译、问答系统和文本生成等。尽管没有针对特定任务进行微调,GPT-2依然能在这些任务上取得良好的效果。
- 伦理考虑:OpenAI在论文中提到了一些潜在的社会影响问题,特别是关于信息操纵和隐私的问题。他们指出,由于模型的强大生成能力,可能会被用来生成假新闻或其他形式的误导性内容。
更多细节,感兴趣同学可以阅读原文。
GPT-2本质上是一个基于transformer 架构的深度神经网络。通过下面代码我们可以查看其网络架构。
from transformers import GPT2LMHeadModel
model = GPT2LMHeadModel.from_pretrained("gpt2") # 加载预训练好的模型
print(model) # 打印模型架构
GPT2LMHeadModel(
(transformer): GPT2Model(
(wte): Embedding(50257, 768) #词嵌入层
(wpe): Embedding(1024, 768) #位置嵌入层
(drop): Dropout(p=0.1, inplace=False) #Dropout层
(h): ModuleList( #解码器块
(0-11): 12 x GPT2Block( # 12个解码器块
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True) #归一化层
(attn): GPT2SdpaAttention( #注意力机制
(c_attn): Conv1D() #注意力得分的线性变换
(c_proj): Conv1D() #投影注意力加权的输出
(attn_dropout): Dropout(p=0.1, inplace=False) #注意力得分的Dropout
(resid_dropout): Dropout(p=0.1, inplace=False) #残差连接后的Dropout
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True) #层归一化层
(mlp): GPT2MLP( #前馈神经网络
(c_fc): Conv1D() #第一层线性变换
(c_proj): Conv1D() #第二层线性变换
(act): NewGELUActivation() #激活函数
(dropout): Dropout(p=0.1, inplace=False) #前馈网络中的Dropout层
)
)
)
(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True) #归一化层
)
(lm_head): Linear(in_features=768, out_features=50257, bias=False) # 线性映射层
)
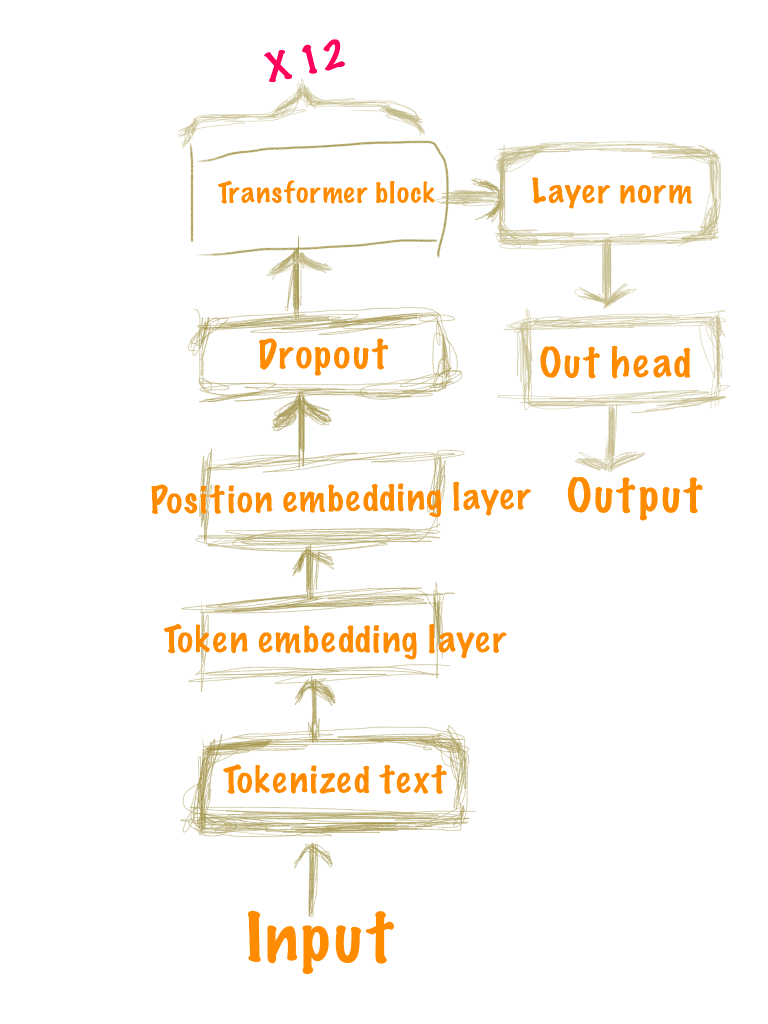
通过上述输出,我们得以一窥GPT-2架构全貌:
- Embeddings – 这一层负责将输入的文本转换成向量形式。包括:
- Token Embeddings – 每个词汇映射到一个向量。
- Position Embeddings – 提供给模型有关词汇位置的信息。
- Transformer Blocks – GPT-2模型由12个相同的Transformer block组成,每个block都包含了:
- Multi-head Attention – 允许模型关注输入的不同部分。
- Position-wise Feed Forward Networks (FFN) – 两个全连接层之间的前馈网络,用于进一步提取特征。
- LayerNorm – 在每个block之后,使用层规范化来加速训练过程并提高性能。
- Language Model Head – 最后一个组件是一个线性层加上一个softmax函数,用于计算每个词汇在词汇表中出现的概率。
基于上述描述,我们给出GPT实现框架:
import torch
import torch.nn as nn
GPT_CONFIG = {
"vocab_size": 50257, # 模型词汇表的大小
"context_length": 1024, # 上下文长度
"emb_dim": 768, # 嵌入层的维度
"n_heads": 12, # 多头注意力机制中的头数量
"n_layers": 12, # transformer 堆叠层数
"drop_rate": 0.1, # dropout比率
"qkv_bias": False # 计算查询(Query)、键(Key)和值(Value)时是否使用偏置项
}
class GPTModel(nn.Module):
def __init__(self, cfg): #此处 cfg 即为GPT_CONFIG
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg)
for _ in range(cfg["n_layers"])]
)
self.layer_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
pos_embeds = self.pos_emb(
torch.arange(seq_len, device='cuda')
)
x = tok_embeds + pos_embeds
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.layer_norm(x)
logits = self.out_head(x)
return logits
class TransformerBlock(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x
class LayerNorm(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x由GPT_CONFIG 可以看出,GPT2依赖的词汇表大小为50257,包含一个12层的transformer块,12 个注意力头,其参数大小为124M。
sum([p.numel() for p in model.parameters()])
124439808接下来,我们对代码进行拆解,带领大家从0构架大模型。