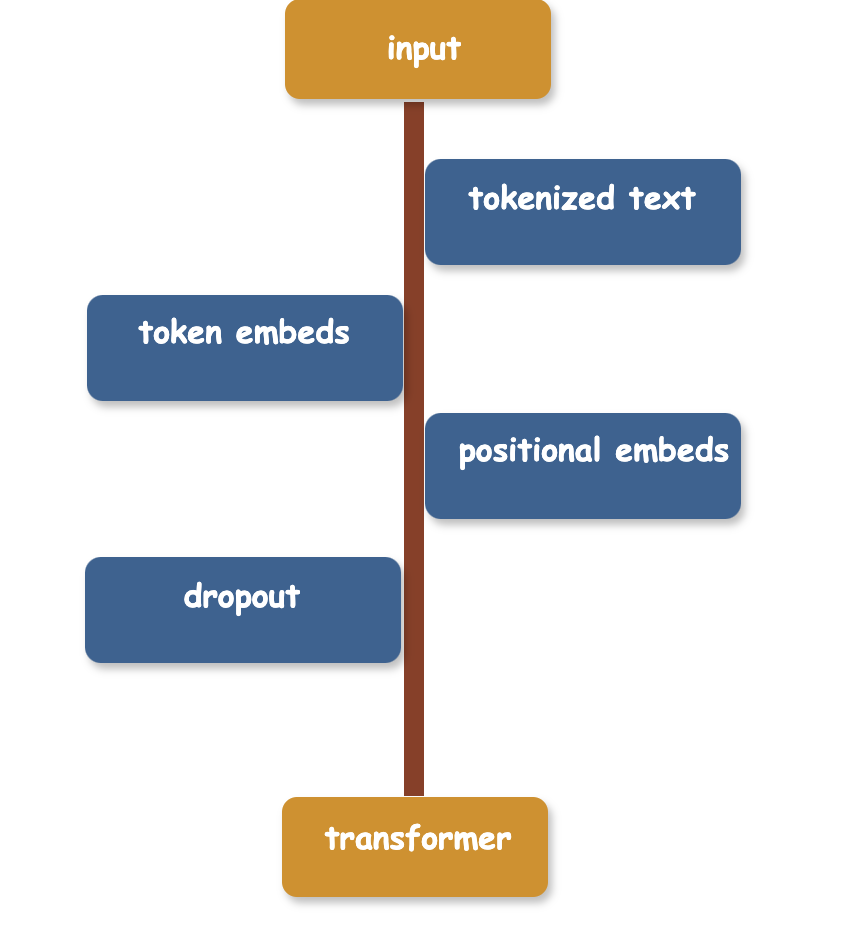
由前文我们知道GPT2使用自回归的方式来进行预训练,在预训练阶段,模型使用了大量的互联网语料。这些语料会先经过一些预处理,具体的,见下图蓝色框内,语料文本(input)会被分割成单独的单词或子词标记(tokenized text),单词或者子词标记转换为标记嵌入(token embeds),同时为了获取标记的位置信息,会继续融合位置嵌入信息(positional embeds),之后经过dropout 层,最终输入给transformer层。
我们将蓝色框内的部分统称为嵌入层。
嵌入(embedding),通常是指将原始离散数据(文本、视频、音频等)转换为高维空间的可学习的,具有固定维度的向量,这种表示形式能够捕捉到数据之间的语义关系。例如,“狗”和“猫”在嵌入空间中可能会彼此接近,因为它们都是宠物;而“快乐”和“悲伤”虽然意思相反,但在情感分析中也可能有某种联系。
没有特殊说明,这里的数据特指文本。
嵌入的作用,本质上是需要将原始数据转换成CPU或者GPU能够处理的数据格式。对于文本来说,其层级划分一般为文档、段落、句子、词组、单词(字),针对每个层级都有相应的嵌入方式,但最常用的是单词级别的嵌入,也称为词嵌入,而句子或段落级别的嵌入在检索领域比较常用,比如用在检索增强生成(RAG)中。
词嵌入技术的发展历程是自然语言处理(NLP)领域中一个充满活力的研究方向,它经历了从简单的统计方法到复杂的深度学习模型的转变。我们简单回顾一下词嵌入技术发展的主要阶段:
初始阶段:基于统计的方法
- 早期尝试:词嵌入技术的起源可以追溯到20世纪末,当时的研究人员开始探索将词语映射到低维向量空间的可能性。其中一项早期的工作是约书亚·本希奥(Yoshua Bengio)等人提出的神经概率语言模型(Neural Probabilistic Language Models),它使用了神经网络来学习词语的分布式表示。
- LLE:罗维斯(Roweis)与索尔(Saul)在《科学》杂志上发表的文章介绍了局部线性嵌入(LLE)方法,这是另一种将高维数据映射到低维空间的技术。
发展阶段:基于神经网络的方法
- Word2Vec:2013年,Tomas Mikolov等人提出了Word2Vec,这是一个革命性的模型,它通过两种不同的架构CBOW(连续词袋模型)和Skip-gram来训练词嵌入。Word2Vec因其简单而有效的实现方式迅速流行开来。
- GloVe:同年,斯坦福大学的研究团队提出了GloVe(Global Vectors for Word Representation),它通过全局统计信息来优化词向量,其结合了全局共现频率统计和局部上下文窗口的优点。
成熟阶段:上下文敏感的词嵌入
- ELMo:2018年,Allen Institute for AI 提出了ELMo(Embeddings from Language Models),这是第一个广泛使用的上下文敏感词嵌入模型。ELMo通过多层双向语言模型来生成词向量,这意味着同一个词在不同的上下文中会有不同的表示。
- BERT:随后,Google的研究人员发布了BERT(Bidirectional Encoder Representations from Transformers),它进一步发展了上下文敏感的词嵌入,使用了双向Transformer架构来处理输入文本。BERT模型因其在多项NLP任务上的卓越表现而受到广泛关注。
最新进展:更强大的模型与应用
- 除了上述模型外,还有诸如RoBERTa、DistilBERT、XLNet等模型,它们在不同的方面对BERT进行了改进,旨在提供更好的性能或更少的计算资源需求。
本篇接下来部分将逐步介绍训练GPT2所需嵌入向量的必要步骤,包括将文本拆分为单词、将单词转换为标记(tokens)、以及将标记转换为嵌入向量。
Tokenized text
对英文文本而言,最常见的文本拆分逻辑是按空格和符号分词,而对中文文本来说,按照汉字/词语和符号分词。
text = "hello world, I like Python!"
pattern= r'([,.?_!"()\']|--|\s)'
split_text = re.split(pattern, text)
split_item = [item.strip() for item in split_text if item.strip()]
print(split_item)
>>> ['hello', 'world', ',', 'I', 'like', 'Python', '!']
#按照单个汉字拆分
text = "你好,世界!欢迎来到2024年。"
pattern = r"([\u4e00-\u9fa5])|([,。!?、;:‘’“”()【】「」『』.,.;:!'\"(){}<>\\-—_@#¥%……&*]+)"
split_text = re.split(pattern, text)
split_item = [item for item in split_text if item]
print(split_item)
>>> ['你', '好', ',', '世', '界', '!', '欢', '迎', '来', '到', '2024', '年', '。']
#按照词语拆分,需要借助专业的分词工具,比如jiba。
text = "你好,世界!欢迎来到2024年。"
split_item = list(jieba.cut(text, cut_all=False))
print(split_item )
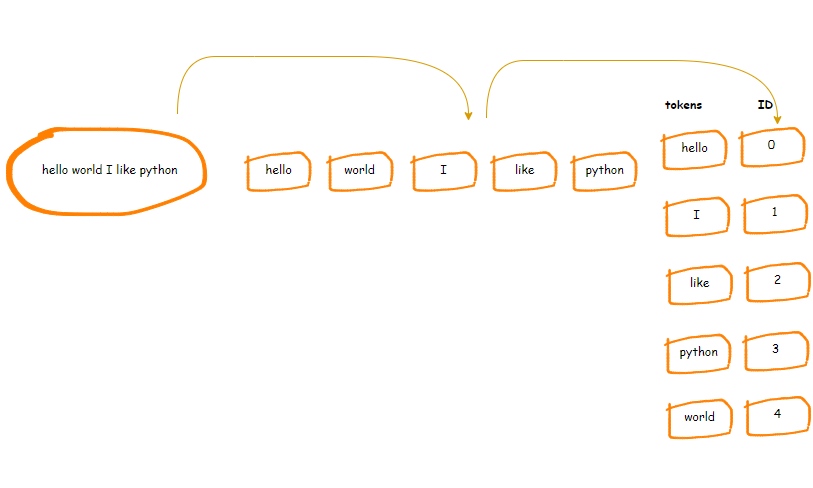
>>> ['你好', ',', '世界', '!', '欢迎', '来到', '2024', '年', '。']拆分后的文本,我们称之为tokens(标记)。
将tokens通过词表(vocabulary) 映射成对应的ID,该ID可以简单理解为tokens在词表中的索引。 前文提到,GPT2的词表大小为50257。一个词汇表示例
词汇表的创建步骤如下:
- 标记集合化:将所有标记放入一个集合中,确保每个标记都是唯一的。
- 排序:对集合中的标记进行排序,通常按照字母顺序排序,但也有可能根据出现频率或者其他标准排序。
- 去除重复:由于前面已经将标记放入集合中,因此这一步实际上是为了确保每个标记都是唯一的。
- 映射到ID:为每个标记分配一个唯一的整数ID。通常,ID是从0开始递增的整数,也可以根据需要进行自定义分配。
- 将创建好的映射保存为文件,以便在后续的训练和推理过程中使用。
以下是一个简单的示例,展示如何创建一个词汇表:
from collections import Counter
import json
def create_vocabulary(corpus):
# Step 1: Tokenize the corpus
tokens = []
for line in corpus:
tokens.extend(line.split()) # Assuming space-separated words
# Step 2: Count the frequency of each token
token_counts = Counter(tokens)
# Step 3: Create a set of unique tokens
unique_tokens = sorted(set(tokens))
# Step 4: Map tokens to unique IDs
vocab = {token: idx for idx, token in enumerate(unique_tokens)}
# Step 5: Save the vocabulary to a file
with open('vocab.json', 'w', encoding='utf-8') as f:
json.dump(vocab, f, ensure_ascii=False, indent=4)
return vocab
# Example corpus
corpus = [
"我 喜欢 学习 自然语言处理",
"自然语言处理 很有意思",
"学习 是 一件 快乐的事情"
]
# Create and save the vocabulary
vocab = create_vocabulary(corpus)
print(vocab)
print(len(vocab))一般的,有了tokens 到ID的映射(称之为encode),还需要建立ID到tokens的映射(称之为decode),即根据ID索引反查对应的tokens。
下面让我们看下,GPT2模型使用的token映射模块。
from transformers import GPT2Tokenizer
# 初始化分词器和模型
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
#下面这种方式更简洁
#import tiktoken
#tokenizer = tiktoken.get_encoding("gpt2")
text="hello world, I like python"
#tokens -> ID
print(tokenizer.encode(text))
>>> [31373, 995, 11, 314, 588, 21015]
#ID -> tokens
print(tokenizer.decode(21015))
>>> python特殊标记
在实际应用中,考虑到词表大小,有些tokens是不在词表中的,这类tokens 被称为 out-of-vocabulary (oov) words ,为了能正确处理他们,通常会使用<UNK>(未知标记)来标识,除此之外还会添加一些其他特殊标记,如<PAD>(填充标记)、<START>(序列开始标记)、<END>(序列结束标记)等。
GPT2 中使用<|endoftext|> 作为序列结束标记(ID 为50256)。此外,GPT2模型使用的分词器没有为词汇表外的词使用<|unk|>标记,它通过字节对编码(byte pair encoding,简称BPE)分词器,它将词分解成子词单元,子词单元汇总到词汇表作为基本词汇。除BEP外,其他标记方法包括WordPiece 标记法和Unigram标记法。
具体原理和使用方法参见以下链接:
Token Embedding
有了tokens ID 之后,就可以通过token embedding 将tokens 映射到高维向量空间,以捕获tokens之间的关系,例如语义相似性、语法功能等。
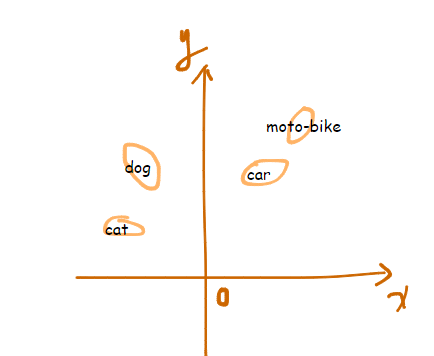
举个例子,我们可以将“dog”和“cat”、“car”和“moto-bike” 映射到2维空间,以计算他们之间的相似距离。
下面通过例子理解token embedding 的工作机制。PyTorch中通过torch.nn.Embedding和torch.nn.EmbeddingBag表示嵌入,EmbeddingBag是 Embedding的一个集合版本。
from torch import nn
import torch
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size, emb_size):
super(TokenEmbedding, self).__init__()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.emb_size = emb_size
def forward(self, tokens):
return self.embedding(tokens)
# 词汇表大小和嵌入向量的维度
vocab_size = 10
emb_size = 5
# 创建TokenEmbedding实例
token_embedding = TokenEmbedding(vocab_size, emb_size)
# 输入的token索引
input_ids = torch.tensor([6, 2, 7, 1, 3])
# 获取嵌入向量
embedded_input = token_embedding(input_ids)
print(embedded_input)
>>>
tensor([[-0.4260, -1.1886, -0.2375, 2.0231, 1.4003],
[ 0.6197, 1.9700, 1.0153, 0.8425, 1.2699],
[-0.3182, -0.6544, -0.5379, -0.6687, 0.3672],
[-0.4898, 0.1482, 0.3474, -0.0741, -1.6905],
[ 1.8046, -0.0952, 2.0150, 0.5448, 0.5242]],
grad_fn=<EmbeddingBackward0>)运行上述代码,会得到一个形状为(batch_size, emb_size)的张量,其中batch_size是输入input_ids的大小(在这个例子中为5),emb_size是嵌入向量的维度(在这个例子中为5)。输出的张量将是输入索引对应的嵌入向量,每个输入索引都会被映射到一个固定大小的向量,此处为形状为(5, 5)的张量。
Position Embedding
基于Transformer架构的模型,输入数据通常是一组词嵌入向量。然而,由于Transformer模型基于自注意力机制(self-attention mechanism),它本质上是顺序无关的(permutation invariant),即它不能仅凭词嵌入向量来区分不同位置的词。因此,我们需要一种机制来告诉模型每个词在序列中的相对位置。
位置嵌入通过为序列中的每个位置添加一个额外的向量,使得模型能够区分不同位置的词。这些位置向量通常是预先计算好的,并且在模型训练过程中保持不变,或者是可学习的,即在训练过程中与词嵌入一起更新。
有两种常见的位置嵌入方法:
- 固定位置嵌入(Fixed Position Embedding):这种方法使用固定的数学公式来计算位置向量。一个著名的例子是Sinusoidal Positional Encoding(正弦位置编码),它在原始的Transformer论文中被提出。
- 相对位置嵌入(Relative Position Embedding):这种方法针对序列中两个位置之间的相对距离进行编码。这种方法的优点在于,它使得模型更容易泛化到不同长度的序列,并且可以更好地捕捉序列中的相对位置信息。
文初的嵌入层框架图表明,位置嵌入通常是在模型的输入阶段添加到词嵌入上的,即输入序列首先通过词嵌入层,然后加上位置嵌入,形成最终的输入表示。
结合词嵌入和位置嵌入(这里通过nn.Parameter 实现了可学习的位置嵌入)的代码示例如下:
import torch
from torch import nn
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size, emb_size):
super(TokenEmbedding, self).__init__()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.emb_size = emb_size
def forward(self, tokens):
return self.embedding(tokens)
class PositionEmbedding(nn.Module):
def __init__(self, max_length, emb_size):
super(PositionEmbedding, self).__init__()
self.positional_encoding = nn.Parameter(torch.randn(max_length, emb_size))
def forward(self, inputs):
batch_size, seq_length, _ = inputs.shape
positions = self.positional_encoding[:seq_length]
positions = positions.unsqueeze(0).expand(batch_size, -1, -1)
return inputs + positions
# 示例
vocab_size = 10000
emb_size = 512
max_length = 1000
token_embedding = TokenEmbedding(vocab_size, emb_size)
position_embedding = PositionEmbedding(max_length, emb_size)
# 输入的token索引
input_ids = torch.randint(0, vocab_size, (32, max_length)) # 假设batch size为32
# 获取词嵌入
token_inputs = token_embedding(input_ids)
# 添加位置嵌入
output = position_embedding(token_inputs)
print(output.shape) # 输出应该是 (32, 1000, 512)Dropout
在处理词嵌入和位置嵌入之后,通常会在叠加的嵌入向量上应用Dropout层,以增加模型的泛化能力。在神经网络中,Dropout是一种常用的正则化技术,用于防止过拟合。
下面是一个完整的示例,展示了如何在叠加词嵌入和位置嵌入之后应用Dropout层:
import torch
from torch import nn
class TokenEmbedding(nn.Module):
"""
见上文
"""
pas
class PositionEmbedding(nn.Module):
"""
见上文
"""
pass
class EmbeddingWithPosition(nn.Module):
def __init__(self, vocab_size, emb_size, max_length, dropout_rate):
super(EmbeddingWithPosition, self).__init__()
self.token_embedding = TokenEmbedding(vocab_size, emb_size)
self.position_embedding = PositionEmbedding(max_length, emb_size)
self.dropout = nn.Dropout(dropout_rate)
def forward(self, tokens):
# 获取词嵌入
token_embed = self.token_embedding(tokens)
# 获取位置嵌入
pos_embed = self.position_embedding(token_embed)
# 应用Dropout层
embed_with_pos = self.dropout(pos_embed)
return embed_with_pos
# 示例
vocab_size = 10000
emb_size = 512
max_length = 1000
dropout_rate = 0.1
embedding_with_position = EmbeddingWithPosition(vocab_size, emb_size, max_length, dropout_rate)
# 输入的token索引
input_ids = torch.randint(0, vocab_size, (32, 1000)) # 假设batch size为32
# 获取叠加词嵌入和位置嵌入的结果,并应用Dropout
output = embedding_with_position(input_ids)
print(output.shape) # 输出应该是 (32, 1000, 512)以上就是整个嵌入层的工作机制。
需要注意的是,词嵌入和位置嵌入矩阵,其实都是待学习参数,这里只不过是给定了初始随机值,在后续的网络迭代中会随之更新。
附录
nn.Embedding
nn.Embedding是PyTorch中用于创建嵌入层的一个类,它主要用于将离散的索引(如词汇表中的单词索引)映射到连续的向量空间中。下面详细介绍nn.Embedding的各个参数及其含义:
参数详解
- num_embeddings (
num_embeddings):- 类型:
int - 描述:表示词汇表的大小,即可以嵌入的最大索引值加1。例如,如果你的词汇表最大索引为999,则
num_embeddings应该设置为1000。 - 示例:
nn.Embedding(1000, 100)表示词汇表大小为1000。
- 类型:
- embedding_dim (
embedding_dim):- 类型:
int - 描述:表示嵌入向量的维度,即每个索引对应的嵌入向量的长度。
- 示例:
nn.Embedding(1000, 100)表示每个索引对应的嵌入向量长度为100。
- 类型:
- padding_idx (
padding_idx)(可选):- 类型:
long或None - 描述:指定一个索引,该索引对应的嵌入向量将被设置为全零向量。这在处理变长序列时非常有用,因为可以通过填充(padding)将所有序列补至相同长度。
- 示例:
nn.Embedding(1000, 100, padding_idx=0)表示索引为0的嵌入向量将被设置为全零向量。 - 注意:
padding_idx的值必须在[0, num_embeddings)之间,或者为None。
- 类型:
- max_norm (
max_norm)(可选):- 类型:
float或None - 描述:如果设置了
max_norm,则嵌入向量将会被重新缩放,使得它们的L2范数不超过max_norm。 - 示例:
nn.Embedding(1000, 100, max_norm=1.0)表示嵌入向量的最大L2范数为1.0。
- 类型:
- norm_type (
norm_type)(可选):- 类型:
float - 默认值:
2.0 - 描述:当使用
max_norm时,计算嵌入向量的范数所使用的范数类型,默认为L2范数。 - 示例:
nn.Embedding(1000, 100, norm_type=1.0)表示使用L1范数。
- 类型:
- scale_grad_by_freq (
scale_grad_by_freq)(可选):- 类型:
bool - 默认值:
False - 描述:如果设置为
True,则在训练期间,嵌入向量的梯度将会被缩放,缩放因子为每个单词在训练数据集中出现的频率。 - 示例:
nn.Embedding(1000, 100, scale_grad_by_freq=True)表示启用按频率缩放梯度。
- 类型:
- sparse (
sparse)(可选):- 类型:
bool - 默认值:
False - 描述:如果设置为
True,则在前向传播时使用稀疏权重更新。这对于一些优化器(如SGD)是有用的,因为它们支持稀疏更新。 - 示例:
nn.Embedding(1000, 100, sparse=True)表示使用稀疏权重更新。
- 类型:
示例代码
下面是一个使用nn.Embedding创建嵌入层并进行前向传播的示例:
import torch
from torch import nn
# 定义嵌入层参数
vocab_size = 1000
emb_size = 100
padding_idx = 0
max_norm = 1.0
norm_type = 2.0
scale_grad_by_freq = True
sparse = True
# 创建嵌入层
embedding_layer = nn.Embedding(
vocab_size,
emb_size,
padding_idx=padding_idx,
max_norm=max_norm,
norm_type=norm_type,
scale_grad_by_freq=scale_grad_by_freq,
sparse=sparse
)
# 输入的token索引
input_ids = torch.tensor([1, 2, 0, 1, 2]) # 其中0是填充索引
# 获取嵌入向量
embedded_input = embedding_layer(input_ids)
# 打印结果
print(embedded_input)nn.Parameter
nn.Parameter 是 PyTorch 提供的一个类,用于将一个张量包装成一个可以随模型一起训练的参数。在 PyTorch 中,模型的参数通常是通过 nn.Parameter 来定义的,这样这些参数就会被自动加入到模型的参数列表中,并且在训练过程中会被自动计算梯度并更新。
参数详解
nn.Parameter 实际上没有显式的参数,它接受一个 torch.Tensor 作为构造函数的输入,并将其转换为模型的一部分
nn.Parameter 的特点
- 自动梯度计算:
nn.Parameter会自动被注册到模型中,使得在模型训练时,PyTorch 能够自动计算并更新其梯度。 - 方便管理:模型的参数可以通过
model.parameters()方法轻松获取,便于优化器(如optimizer)使用。
示例代码
使用 nn.Parameter 来定义模型中的参数,并通过优化器更新这些参数
import torch
from torch import nn
class ParameterModel(nn.Module):
def __init__(self):
super(ParameterModel, self).__init__()
# 使用 nn.Parameter 定义一个可学习的权重矩阵
self.weight = nn.Parameter(torch.randn(10, 5))
# 使用 nn.Parameter 定义一个可学习的偏置向量
self.bias = nn.Parameter(torch.zeros(5))
def forward(self, x):
return x @ self.weight + self.bias
# 创建模型实例
model = ParameterModel()
# 假设输入数据
x = torch.randn(3, 10) # 假设batch size为3
# 前向传播
output = model(x)
print(output.shape) # 输出应该是 (3, 5)
# 创建一个优化器来更新模型参数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 假设有一个损失函数
loss_fn = nn.MSELoss()
# 假设有一些目标数据
target = torch.randn(3, 5) # 假设batch size为3
# 训练循环示例
for epoch in range(10): # 假设训练10轮
# 前向传播
output = model(x)
# 计算损失
loss = loss_fn(output, target)
# 清空梯度
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 打印损失
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")nn.Dropout
参数详解
nn.Dropout 的主要参数是 p,表示每个神经元被暂时关闭的概率。默认情况下,p 的值为 0.5。
nn.Dropout 的工作原理
- 训练模式:
当模型处于训练模式(即调用 model.train())时,nn.Dropout 会按照给定的概率 p 随机关闭神经元。
- 推理模式:
当模型处于推理模式(即调用 model.eval())时,nn.Dropout 不会对输入做任何改变,即直接返回输入张量。
这是因为在推理时不需要引入随机性,模型应该尽可能准确地预测。